 Bertrand Ibrahim,
Ph.D.
Bertrand Ibrahim,
Ph.D.E-mail: Bertrand.Ibrahim@cui.unige.ch
URL: Bertrand.html
 Stephen D. Franklin,
Ph.D.
Stephen D. Franklin,
Ph.D.E-mail: franklin@uci.edu
URL:
http://www.oac.uci.edu/indiv/franklin/
In this paper, we analyze those features of WWW that are most interesting for educational purposes and show possible sophisticated pedagogical uses of the web.
Long before WWW had reached wide acceptance, the Internet was being used for educational purposes, mostly via mailing lists and bulletin boards. In spite of its tremendous growth, WWW is still only marginally used for teaching and learning activities, probably even more so in Europe, where very few primary or secondary schools have access to the Internet. In this regard, WWW is acting as a driving force, since its ease of use makes the Internet trivially accessible to pupils with no prior knowledge of computers, programming or even networking, making it more tempting for teachers to take advantage of it.
This access by young pupils to the Internet raises some issues, both ethical and technical: can one allow minors free use of a facility that can potentially give them access to pornographic material? Or that makes it very easy for them to pull huge amounts of data accross long distances without their realizing the costs and consequences of their actions? Should one therefore limit their access to the Internet to class work, where a teacher can ensure they are not misusing the facility?
These features and their attractiveness, for education in general, as well as for distance learning, have already been discussed at length in the past and will therefore not be discussed any further in this paper.
A new feature that has been added recently to HTML is the possibility to include, in a document, input fields that the reader can fill out and the contents of which will be transmitted to the server when the reader pushes a "submit" button. This fill-out form capability has been essential in allowing new uses of the web, where the user can be more active than just clicking on sensitive areas of a document.
One potential difficulty for teachers in using forms to create "interactive" documents is that the use of forms requires some programming on the server to handle the requests (generated by the forms these teachers would like to include in their WWW-based courses) and process the information entered by the user. As a help to people who are not knowledgeable about cgi-bin scripts programming, one can find CGI-compliant programs (e.g. the Zot-Dispatch automatic form handling script generator, available from the University of California, Irvine) that will automatically generate the cgi-bin script appropriate to handle the results sent via a form. Unfortunately, these tools are not always general enough to allow sophisticated handling of the information provided by the user. They typically allow field substitution in a template document that will either be emailed to an address or list of addresses, or sent back to the user, or appended to a file. Some have gone further than this, developing tools to automatically convert applications with GUIs to fill-out forms coupled with cgi-bin programs [thr94].
In an advanced educational setting, one will want more complex handling. For instance, we are currently working on the design of a tool that will allow teachers to not only specify interactively their forms via a regular WWW viewer, but also specify, with a symbolic formalism, free-text answer analysis criteria that will be applied to some user-entered form fields to select appropriate response documents, in addition to modifying these response documents on-the-fly, based on some other user-entered form fields as well. This tool will also generate automatically the cgi-bin scripts that will handle the information sent via the forms, and possibly pass that information via sockets to programs that would be running on the WWW server, a mechanism we have used in a former project, in which we allowed students to control remotely, via WWW, example programs that were described in their Data Structure class.
Another, even more recent, feature that is of interest in an educational setting is the ability to run a WWW viewer in "kiosk mode", by which the browsing can be limited to some specific set of documents. This is obviously one way to solve the problem of giving pupils access to the Internet without having to fear questionable uses that could provide arguments to those people who are opposed to giving Internet access to schools under the pretext that it would give minors uncontrolled access to pornographic or violence-related documents, while the school is paying for these resources.
There are however structured ways [1] in which WWW can be used for education. Two main approaches come to mind: on one hand, using the technology on a closed corpus of educational material, mostly for the hypermedia and distance delivery capabilities of WWW and, on the other hand, using the technology to access, in a structured way, an open corpus of material that was not necessarily meant initially to be used for specific educational purposes.
One characteristic of WWW that can appear as a limitation is the fact that the HTTP protocol is stateless, that is, there is no direct relationship of any kind between two consecutive requests to the same server, even if the queries come from the same user. The server treats every request it receives independently from any other request it received in the past or that it will receive in the future. This statelessness allows the HTTP server software to impose very little overhead on the server machine, and keeps the protocol between the client and server very simple.
However, good educational material should take into account the background of each learner to tailor its behavior to the learner's capabilities and past history, and to provide appropriate remediation to learners who experience difficulties with some concepts. To achieve this, the educational software has to keep track of the users' states and actions, which seems to contradict the statelessness of WWW. The solution we developed to overcome this difficulty has been to combine the fill-out form capability with the possibility for the HTTP server to execute external programs or shell scripts in response to a request.
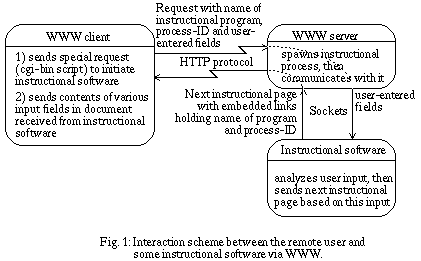
Normally, when the HTTP server executes an external program or shell script, it waits until the program is finished to send the program's output as a virtual HTML document. In our case [ibr94], to maintain a state between consecutive requests, the external shell script spawns a child process that will continue executing during the whole educational sequence. The output of the child process is passed to the HTTP server as a virtual HTML document. The hyper-links embedded in this document contain the process Id of the child process. With this information, the shell script invoked by the HTTP server on a later request can reconnect to the spawned child process and pass it the rest of the request data that will contain information provided by the learner. This mechanism is described in Fig. 1:
The approach we have just described has its advantages and its drawbacks. Among the advantages we find the portability achieved by using HTML for the spawned process output. Whatever the machine the user is working on, the viewer should be able to handle HTML documents and thus be able to display the output of the educational process, regardless of the hardware of the machine. There is therefore only one executable version of the courseware, that resides on the server machine. As a consequence, anybody can engage very simply in the educational process, from anywhere in the (Internet) world, at any time, without any bootstrapping procedure. One drawback is that this server machine can become overloaded and thus unable to serve new users. Another drawback is that the user interactions and the program output are limited by the HTML syntax.
Another approach to the closed corpus option is to define a new document type and have a special dedicated viewer handle the "document" sent by the HTTP server. This viewer can be an interpreter for some special purpose language and it will use the document sent by the server as a program to interpret/execute on the client machine, thus removing the load from the server. This external viewer can send a specific system signal to the main WWW viewer to tell it to display a new document, the URL of which has been put in a temporary file. When used in combination with fill-out forms, this allows bidirectional communication (via the WWW server) between the main WWW viewer and the external viewer that are both running on the same client machine. A more effective scheme is currently being proposed as a Client Communication Interface (CCI) protocol, that should allow bidirectional communication between a WWW viewer and an external application, without necessarily transiting throught a WWW server.
The main advantage of this approach is that it can potentially use all the graphical and computational capabilities of the client machine, thus resulting in more powerful user interfaces and faster response times. The drawbacks are that one needs to have a dedicated viewer on the client machine (this viewer has to be downloaded by the users/learners before they can start the educational process, or it has to be pre- installed by the teacher or the local system manager), and that a different executable version of the interpreter has to be produced for every different kind of hardware that the learners can potentially use. Another possible drawback could be related to security issues if the interpreter can potentially execute instructions that would harm the local computer environment (software viruses).
Given its gigantic size, this ocean of information has to be harnessed to make it manageable and useful to users and learners. In this regard, WWW appears to be very useful in that its network-based hypertextual capabilities make it very appropriate to organize into a hierarchy this huge volume. CERN [2] has started a very interesting project called the WWW Virtual Library. Its purpose is to create a distributed catalogue of all the Internet resources accessible via WWW. It is maintained on a voluntary basis by people who are specialists in a specific domain and who are willing to share and maintain a document, or a hierarchy of documents, that reflect a certain structure of their domain, giving access to all the major Internet-accessible resources that they are aware of. The subjects of the WWW Virtual Library range over a very wide spectrum, covering most regular subjects of study, as well as recreational subjects or more esoteric ones like "Paranormal Phenomena" or UFOs.
Electronic journals and online magazines also constitute interesting sources of information that are probably going to develop and grow as people get more accustomed to the electronic media.
As useful as they may be for researchers or post-graduate students, these structuring resources are probably not directly usable as is for more basic educational purposes. They are nevertheless a good example of what can be done to present a subject to people who want to learn about it. One can easily imagine developing more elaborate structural documents that will guide learners in their exploration of a subject domain. The educational material would thus consist of a combination of explanatory text, pointers to more in-depth material publicly available on the Internet and, possibly, some features of the closed corpus approach by which the learner could be evaluated and proposed complementary or remedial material.
An interesting pedagogical strategy [wra94] one can use in the open corpus approach is to have pupils use WWW in their process of knowledge appropriation [3] by giving them the task to create their own documents that will tie together the information they have collected in a more constructive way than just enumerate pointers to existing documents [4]. These synthetic documents (in the sense of documents synthesizing the content of other documents) created by pupils can also help the teacher have a better grasp of the pupils' mental structures. Even more important, the pupils' documents can help the teacher offer appropriate remediation to those pupils who have not been able to go far enough in their discovery of a subject.
However, for this to happen, there is a need for appropriate tools that will make it much easier for teachers to integrate forms in their hyperdocuments and produce the corresponding cgi-bin scripts and programs to handle the data collected with these forms.
As for the ethical and technical issues that are raised by having youngsters gain potential access to "undesirable" documents or pull huge amounts of data over long distances, we have shown that technical solutions existed that should reassure educators and allow them to give their pupils open but not unlimited access to the Internet, even outside the classroom. The kiosk mode makes it possible to limit the access to a more or less controlled set of documents, making it virtually impossible to reach those servers that distribute offending documents.
The problem of excessive network traffic could be resolved in the same way, but limiting the access to servers that provide only "reasonably sized" documents is probably too drastic. Ideally, the WWW viewers should include the possibility to limit the size of the documents that can be retrieved. The HTTP protocol allows it already, since a WWW client can use the HEAD request method to get, among other information, the size of a document. The authors are however not aware of any WWW viewer that implements such a capability.
Site Hosting: Bronco