Semiformal Visual Languages, Visual Programming at a Higher Level of Abstraction
Note: paper presented at the Fifth
Conference of the ISAS (Information Systems Analysis and Synthesis) /
The Third Conference of the SCI (Systemics, Cybernetics and Informatics),
Orlando, Florida, USA, July 31-August 4 1999.
This paper is also available in PDF
format, compressed with gzip.
Abstract
This paper intends to focus on the visual programming aspects of a courseware development environment and discusses which concepts can find a more general applicability for visual programming in other domains. To achieve this, we first introduce the concept of semi-formal visual language, on which our environment is based; we then analyze the differences and similarities between courseware and other kinds of software, then describe our tools and methodology, then see how they can be used in a broader scope, and finally explain how they can be enriched to broaden their applicability.
The computer-based development environment described in this paper is now operational and we will try to draw more general conclusions from this experience in regard to the use of semiformal visual languages, i.e. a combination of a visual representation of software and natural language.
Keywords
Semiformal language, visual specification, control-flow, data-flow, development environment, automatic programming
Introduction
Spreadsheets are an interesting milestone in computer
science in that they were among the first programming tools designed to be used
by people who were not computer professionals. In order to be widely used,
these programs had to be simple enough to use, but powerful enough to be
genuinely applicable to real-world problems and not just toy applications.
In our century of communication, image is a predominant
vehicle for information. The world of computers is also getting more image- and
graphics-dominated. After icon based command languages and graphical user
interfaces, visual programming environments are now becoming more popular.
The best candidates for visual programming techniques
are, by far, those fields where a graphical description formalism existed prior
to the introduction of computer tools. Long before we decided to create a
computer based development environment to support our methodology and reduce
our development costs [10][11], we
already used a graphical description formalism for the specification of
computer based learning (CBL) lessons.
One can already find nowadays a few visual programming
environments, available on PCs and graphical workstations, spanning a wide
range of levels of abstraction. Some are indeed comparable to usual general
purpose programming languages, mapping graphical structures over regular
programming structures [2][3][4][5][7][8][17][18][21], and others,
more application oriented, have a level of abstraction that is closer to the
problem domain [9][14][15][20].
Even if they have a more friendly user interface, these
visual programming languages are still programming languages, and as such,
require a certain level of expertise from their users. If, as for spreadsheets,
we want to make a visual language more widely used, we have to keep it simple
enough to be usable by people without a computer science background. The
problem, then, is to find the best trade-off between the simplicity of the
language and its power of expression.
An alternative to this trade-off is to stop considering
the visual representation as a programming language, but rather as a semiformal
specification language by adding a natural language component to the graphical
formalism. The visual language is then no longer a programming language, but
merely a specification formalism. (Specification is used here in a broad sense,
since it actually covers most of the design and, ideally, the major part of the
implementation).
The formalism is thus not totally graphical, but there
are different advantages in adding a natural language component: firstly, it
helps in keeping the overall language simple; secondly, it allows the
"domain-experts" to keep the specification relatively close to the
problem level rather than forcing them to attempt a detailed solution at a
programming level. The specification thus remains limited to specifying actions
lying in the application domain.
The simplicity comes from the fact that it is not necessary to include in the graphical formalism all the constructs needed to use it as a general purpose programming language. The natural language component is there to allow the domain-experts to specify relatively complex actions without having to make explicit the "how", but just the "what" (and perhaps the "why"). As in [19], we believe that asking the user to input a program completely graphically can be rather cumbersome and undesirable. Of course, the more that can be done without resorting to the natural language component, the better (except, maybe, for documentation). The visual language should thus include most of the basic primitives required for the type of application it is used for, at the highest possible level of abstraction. To keep the language simple, it is the author's belief that the number of different basic elements of the language shouldn't exceed five to ten, and the way these elements combine shouldn't follow rules that are too complex. If these requirements are not met, the language becomes too complex to be easily used.
The price to pay for this simplicity is that further programming is needed after the specification has been written. This is not necessarily a bad thing since the domain-experts are often not skilled programmers. As such, they are probably not aware of all the pitfalls of the programming activity and the notion of software engineering is most probably foreign to them.
How much additional programming is needed after the specification has been written depends very much on the primitives available in the visual language and on the type of application that is being developed. For large scale projects, that are, by nature, a team effort, it makes perfect sense to use domain-experts for the specification and the design of the software and programmers for the actual implementation. The graphical specification can then not only be used to make the link between the domain-experts and the programmers, but can also be used to obtain a partial initial implementation by using automatic programming techniques to convert the formal part of the specification into executable code. Artificial intelligence techniques can also be used to convert even some of the non-formal part of the specification into executable code. The automatically generated code should be executable as is, giving a rough idea of what the final product will look like. This technique allows the domain-experts to do rapid prototyping and undertake a few design review cycles even before any "low level" programming has been done.
With this approach, it becomes important to have computer tools supporting the whole life-cycle of the development of an application. Indeed, one has to keep a tight link between the visual representation and the handcoded parts. Interactive multi-window editors that link the different components together can prove very useful. One interesting aspect of this approach is that it allows for a continuous enhancement of the automatically generated prototype to get to a complete implementation by what is called in
[6] "evolutionary prototypes". Indeed, the prototype obtained with the automatic program generator is not a throwaway prototype, but rather a skeleton to which code will be added to get the final complete implementation of the program. This is very useful in a context where the people working at the design level are not necessarily working at the implementation level.
In some ways, this is an extension of what has already been done for many years now for the design of user interfaces (graphics, text, voice, sound, video or a combination of these) by using state transition diagrams, first as a paper and pencil methodology [16],
and, later, with computer supported tools [13][22]. The major difference being that these visual programming methodologies were meant to be used by programmers to ease the design and the implementation of their programs. Therefore, the visual formalism was designed as a formal notation to build the actual implementation of the application. There was thus no room for natural language in the specification and the visual language had to allow for the specification of the lowest levels of details of the algorithm under construction. For instance, in
[13], the diagrammatic component of the formalism is completed with a more classical textual programming language. Similarly, in
[22], the state transition diagrams only specify the user interface of the application; the rest of the application still has to be designed and implemented in a traditional way.
Visual programming of courseware
Current authoring systems have a common point with spreadsheets, in that they are also meant to be used by others than computer professionals. The bulk result of this approach is that these authoring systems are quite restrictive as to what the courseware domain-experts can ask the system to do [20]. Those systems, that provide the "users" with more general programming facilities, don't integrate very well the programming component with the rest of the system. To say that these programming features do not follow modern software engineering practice is an understatement.
With such authoring systems, developing courseware is very much like handicraft. The craftsmen-teachers directly implement their courseware with the tools that will save them as much work as possible. With little or no background in programming or in software engineering, they will naturally limit themselves to rather small modules often only useful to their author.
Developing courseware in the large, for instance a complete curriculum, requires a much more complex and methodical approach to programming, very much like any programming in the large. One has then to consider that different individuals are involved, with various backgrounds and with different understandings of what can be done with a computer and how it can be done. Another important factor is that the domain-experts might not be available anymore when the courseware is operational and needs improvement, adaptation or debugging.
Courseware is a very special kind of software, in that it aims at effecting changes in its users rather than in their environment, while other kinds of software actually strive for the opposite, that is, let the user adapt the tool rather than have the user adapt to the tool. Courseware is therefore (or at least should be) very interactive, involving a very high proportion of input and output operations and a good amount of condition evaluation to make it as non-linear as possible in order to adapt to the user's profile and capabilities. Actually, most interactive software should have these characteristics.
Courseware development in the large has some specificities that make it different from other software. First of all, courseware can include hours of very varied interactions with very few repetitions, whereas more general user interfaces will commonly involve a limited number of situations. Secondly, the design of general user interfaces focuses mostly on the response to a correct user behavior, whereas in courseware, one must pay a lot of attention to the mistakes of the user. Good courseware should thus, often, vary its response to identical user input, mainly when it is a mistake on the part of the user. Indeed, if a learner repeats the same error, it may well be that the help he/she got from the system the first time wasn't appropriate to make him/her correct the misconception that induced the error (even though this also holds for any kind of software, it is often seen as particular to courseware). Thirdly, the design of courseware will generally be done by people whose primary domain of competence is not programming. It would therefore be an error to want to have the courseware domain-experts specify all the implementation details during the design phase.
With all its specificities, courseware development can benefit a lot from the use of visual representation techniques. Like Wasserman
[22], we extend simple state transition diagrams (in our case, to fulfill the needs of courseware design). But we do not try to follow a completely formal syntax. Instead, we introduce a natural language component in the formalism to keep this formalism simple, and, in addition, to have a higher level of abstraction in the specification.
An example: the IDEAL development environment
The project described in this section was the result of a long experience in developing large Computer Based Learning (CBL) applications in a rather "traditional" way. This project intended to tackle the software development life-cycle of CBL lessons to allow educators (the domain-experts) to concentrate on the pedagogical aspects of the lessons. It is based on a visual representation of CBL lessons and illustrates quite well what has been said in the previous sections.
In order not to impose any limitation on the teachers who want to develop CBL lessons, we initially chose to use a two phase approach in which the teachers specify the behavior of a lesson in a detailed script (pedagogical design phase) and then a team of programmers implement this script using a general purpose programming language (coding phase).
An initial, simpler, version of the visual formalism we use in this project was invented by Prof. A. Bork and his team, at the Educational Technology Center of the University of California at Irvine [1]. It is independent from any programming language and is precise enough to give an exact description of the conversational flow of the final product, i.e. the lesson. In order to make it easier for teachers to master it, the formalism comprises very few basic primitives and includes a natural language component. Both aspects allow it to have an abstraction level very close to the conceptual level of the problem, i.e. computer based learning.
Although simple, this formalism allows for a complete and detailed description of a lesson (partially in natural language). Similar to a movie script, but much less linear, the dialogue between the computer and the learner can be described semigraphically. A script is thus a kind of typed directed graph and bears some resemblance to the extended state transition diagrams described in [22]. The nodes of the graph usually contain actions and the edges represent the flow of control of the program. The graphical decoration of a node indicates the type of action that is described in the node. The formalism is based on the following basic elements:
Message: a message is just a short piece of text that will be displayed, to the end-user, on the screen (it may include layout directives). The text of the message will be stored separately from the program since it might be translated later into other natural languages. This way, the program only contains references to messages (their names) rather than the text of the dialog itself. In a specification, messages are displayed on the screen without any graphical decoration around them.
Directive: a directive is some text describing an action that has to be done by the program. This action can be very simple (e.g. read a string from the keyboard, or some other elementary action very common to CBL programs) or much more complex (e.g. invoke a spreadsheet simulation, show a complex picture or an animation,...). Directives are usually given in free form and are graphically represented by text surrounded by curly brackets (e.g. {clear screen}).
Subgraph reference: a subgraph reference is used to invoke another script that should be executed at the place where the reference is. This allows a hierarchical decomposition of a specification into smaller and more manageable pieces. Subgraph references are graphically represented by a script name between angular brackets (e.g. >ForwardMailIntermediate<, where "ForwardMailIntermediate" is the name of the subgraph to invoke).
Comment: a comment is a node containing text that documents the script and makes it more easily understandable to human readers. It explains, for instance, what is done in a certain section of the script and why it is done. This is important in an environment through which people with different backgrounds collaborate. Comments are graphically represented by text between parentheses (e.g. (this script allows the user to create a new mail folder)).
Condition: a condition is a predicate (also referred to as a test). It is generally based on the learner's answer (e.g. possible answers, presence of some keywords, ...) and is given either in natural language or in some other symbolic pattern matching formalism. Conditions are graphically represented as text in a rectangular box. They are usually grouped vertically in adjacent and connected boxes that are evaluated in sequence from top to bottom until one of the predicates evaluates to true, in which case the evaluation stops. Each test box is connected to one or more direct successors on its sides by labeled arcs. A counter is implicitly associated with each predicate and is incremented at runtime each time the predicate evaluates to true. See Fig. 2 and Fig. 3 for some examples of the use of condition nodes.
Media
: a media node describes an audio-visual item such as a sound, an image, a video sequence from a laser disc or an animation (in various formats: AVI, Quicktime, MPEG, etc.). It specifies the type of medium plus all the information necessary to use the medium. Media nodes are graphically represented by text between tildes.
Edge: an edge is a directed arc connecting two nodes. It is used to indicate the flow of control in the software. Each edge originating from a test box can be labeled with a number (integer) or a sequence of numbers. At run-time, when the predicate of the text box evaluates to true, the value of the associated counter will indicate, based on the edge labels, which edge on the side of the box has to be used to find the next action to take. An implicit and invisible edge connects a test box to the adjacent test box that is just below it. The purpose of this arc labeling is to avoid infinite loops and to vary the behavior of the program if the learner repeats the same mistake.
Each element of the formalism has its own graphical representation that indicates the type of action performed by the element. To clarify things, the reader will find in Fig. 1 a small example of a script taken from a project of a self-instructional electronic mail system. As one can see, the basic information conveyed by the visual representation is the flow of control and what type each node is (e.g. message, directive, test, etc.). The two first nodes are purely comments. Then comes a cascade of test boxes that will determine the behavior of the program, based on the current situation of the learner as well as on his/her last input. (This example is not typical in its size, as scripts tend to have much more nodes).
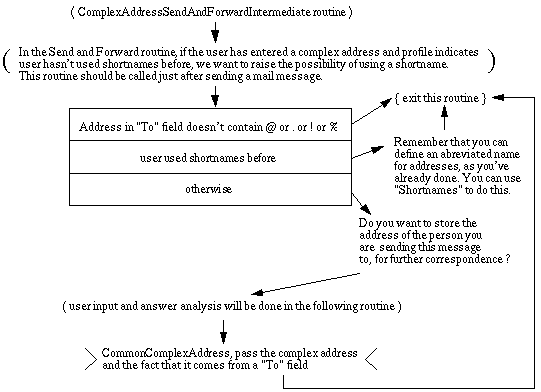
Fig.1: Example of a (very) small script that illustrates the combination of visual formalism and natural language to form a high level specification.
A script is internally stored as a directed graph structure with typed nodes. The automatic program generator then translates this graph into code implementing a finite state automaton. Each state of the automaton contains the execution of the action specified in the corresponding node of the graph and each edge can be translated into a change of the state variable of the automaton.
An important aspect of the program generator is its ability to produce source code in different commonly used programming languages to easily adapt to what is available on target machines. The constraints that dictate the choices of a programming language are partly induced by the way the code will be generated. The target language has to be modular to allow a clean separation of automatically generated code and "handwritten" code.
The states of the automaton at which a nontrivial action has to be executed are each coded as a call to an external procedure. For such an external procedure, the program generator produces a temporary implementation that will work as a prototype and that programmers will have to replace by an actual implementation.
A synchronous editor is available to help programmers write these external procedures. Different windows show the different views of the same thing: a regular text editor in one window to edit the programmers' code and the script editor in another window to show the corresponding specification. The purpose of the synchronous editor is to overcome the difficulty in using code produced by an automatic program generator (which is hardly readable by a human being). To avoid having programmers deal with automatically generated code, the parts that have to be programmed are in separate modules.The programmer can thus very easily see, write or modify the code corresponding to a specific part of the script by finding the location in the script window and then asking for the module window to show the code for that part of the script. One can also find a specific location in the code (e.g. where an error occurred) and then ask for the script window to show the part of the script which specifies that part of the code.
With this tool, the programmers can always see the specification at the same time as they see the code they are working on. This specification (the script) should help them understand and manage the code, since it can be seen as a human readable description of the code. Moreover, this approach also encourages the domain-experts to keep the specification up-to-date with the code. Indeed, the fact that the graphical specification is easily modifiable with an appropriate tool and that the specification and the code are tightly coupled makes the developers less inclined to patch the code directly as they might be tempted to do if the specification were an independent document. In addition, a version management mechanism integrated to the synchronous editor allows the programmers to easily find the places where the specification has been modified since the last implementation was completed. They are automatically shown the changes in the specification, one at a time; they can then find the corresponding code via the synchronization mechanism and adapt the implementation accordingly.
Run-time considerations
Different approaches to visual programming are possible. The first two that come to mind are: the use of an interpreter with an integrated graphical editor, or the use of a graphical editor and a separate graphical compiler. In both cases the graphical editor would manage an internal structure representing the visual program. This internal structure can then be either directly interpreted, or translated into source code for a given conventional programming language. The methodology described in the previous section is applicable to both the interpretation and the compilation approach.
For those cases in which the visual language is not powerful enough to fully specify the behavior of an application, a conventional programming language is generally used for the lower level programming. Part of the specification of the application can then be written using this programming language, possibly in a textual form. Such a code fragment could be visualized as a specific kind of icon in the visual specification.
If the visual language is interpreted, it is sensible to choose an interpreted conventional programming language to go with it. The interpreter for the conventional programming language would then have to be integrated into the graphical interpreter to allow the latter to invoke the former for a code fragment item of the visual specification. An easy solution is to write the graphical interpreter with the same interpreted programming language as the code fragments. The graphical interpreter then just needs to pass the text associated with an icon, representing a code fragment, to the programming language interpreter.
If the visual language is compiled, it seems better to use a modular target programming language. This way, the code needed to complement the visual specification of the application could be given in separate modules and compiled separately from the automatically generated code. This solution is more flexible than using a graphical interpreter since the programming language for the graphical compiler need not be the same as the programming language used on the target machine. The graphical compiler can even be table driven in order to generate source code in different target languages, which allows the developers to adapt to whatever programming language is available on a target machine.
Another aspect that is worth noting is the separation between the development and the runtime environments. Even though the compilation approach has its drawbacks, the fact that we want to be able to develop software for many different target machines makes it mandatory to have this separation if we do not want to have to port the whole development environment to each different target.
Usability of the formalism for conventional programming constructs
The "condition" node type described in section 3, in conjunction with the definition of a predefined predicate named "true" that always evaluates to true (synonyms like "otherwise" are also accepted), allows for the construction of most branching and looping constructs found in common programming languages, as in Fig. 2 (we use here a pseudo-syntax close to Pascal and Ada).
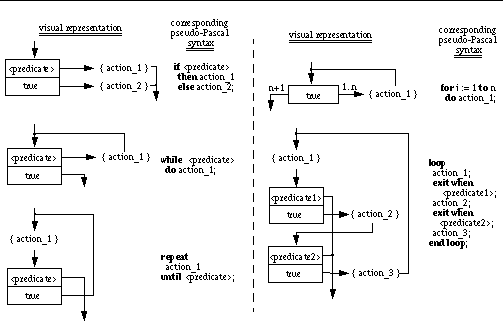
Fig.2: Visual representation of regular branching and looping constructs
To ensure completeness, the following semantics have been attached to the labels over the edges originating from the lateral sides of a test box: in the absence of a label, a default label of "1" is assumed; each label can represent a single integer value or a range; the ranges corresponding to the set of labels associated with all the edges originating from the same test node must not overlap (i.e. there should not be any ambiguity as to which edge corresponds to a given counter value); the first time the predicate in a test node is true, the associated counter is assigned the lowest value in the lowest range defined by the labels of all edges originating from that node; for the following times that the predicate evaluates to true, the counter is incremented by one, unless it has reached the highest value in the highest range; the control flow follows the edge that is labelled with the value, or an interval containing the value, of the associated counter; if there are gaps in the various intervals and the counter value falls within one of these gaps, control flow follows the edge labeled with the highest value that is still lower than the counter value
With these little examples, one can see that the main advantages of this visual representation are that it is simple and generalizable: the same basic graphical construct can be ubiquitously used for many different programming constructs. The simplicity of the formalism can be even more striking on more complex examples. For instance, the reader can try to figure out the syntax in a conventional programming language for the diagram in Fig. 3.

Fig.3: Example with complex logics
Data-flow representation
The control-flow formalism that has been described in the earlier sections was initially designed with courseware specification in mind. It has successfully been used in rather large CBL projects and has also been used for a more general domain of application where education was not the only focus. Now that we have started to use it for more general program development, such as self-instructional software, the need for a representation of the flow of data between the various parts of an application has become more acute. We have therefore defined a visual representation for data structures that is the basis for the superimposition of a data-flow description on top of a control-flow description.
To avoid cluttering the display, it didn't seem desirable to us to have both data and control flow visible at the same time. The nodes remain at the same place when the user of the visual editor switches between the two views, only the edges connecting them change.
However, it is possible to establish point to point data-flow connections as well as define and examine the parameters of a node while in the control-flow view.
For a detailed data-flow description, we have developed a data structure visual formalism and we are now working on the corresponding editing facilities [12].
Conclusion
The visual formalism described in this paper has been successfully used for over twenty years in rather large computer based learning projects without much change until software tools were developed to support it. The use of visual programming techniques prompted us then to refine the visual syntax in order to give more expressive power to the visual information (mainly to add new node types). Our past experience has shown that this formalism is very easily used by people who have little or no background in programming. Our current experience shows that people who have already used this formalism with pencil and paper really appreciate having computer tools to help them.
It is interesting to note that the introduction of computer tools led us to extend the visual aspect of a formalism that existed prior to these computer tools. In addition, these new tools changed the way people managed their work, mainly in the design phase. Indeed, the use of computer tools encourages domain-experts to build a more modular description of the software they are creating.
Although it is not commonly done in visual programming, we are convinced that the combination of a visual representation with natural language leads to a clearer description of software than strictly visual languages would allow. This combination helps in keeping the description at a high level of abstraction, making it more readable by other people. It also helps in saving the domain-experts from having to specify too many details that pertain more to the implementation than to the specification or to the "problem level" design. The main risk here, is to have ambiguities in the description of the application.
For instance, in our case of courseware development, the domain-experts may leave various matters undecided at the level of the lesson. It is not infrequent that implementors have to consult the designers, to try to resolve questions that the domain-experts had failed to handle, or maybe even to notice. The synchronous editor is very useful in this case, as it bridges the communication gap between the various people involved. Evolutionary prototyping can, in some ways, also help in that it allows the domain-experts to test the implementation already before or during the implementation phase and not just after everything has been coded. One can therefore hope that ambiguities of the specification can be discovered at an earlier stage, and thus reduce the cost of the corrections.
Using a pure control-flow description for applications other than courseware showed its limitations: all the information passing between various parts of the software had to be done "behind the scene", i.e. it did not show in the visual specification. Complementing it with data-flow and data structure descriptions has greatly broadened the scope of applicability.
Bibliography
-
Alfred Bork, Harold Weinstock, editors; "Designing Computer Based Learning Material"; Springer Verlag, 1986.
-
Gretchen P. Brown, Richard T. Carling, Christopher F. Herot, David A. Kramlich, Paul Souza; "Program Visualization: Graphical Support for Software Development"; IEEE Computer, Aug. 1985, pp 27-35.
-
Raymond J. A. Buhr, Gerald M. Karam, Carol J. Hayes, C. Murray Woodside; "Software CAD: A Revolutionary Approach"; IEEE Transactions on Software Engineering, Vol 15 No 3, Mar. 1989, pp 235-249.
-
George W. Cherry; "S-R Machines: A Visual Formalism for Reactive and Interactive Systems"; ACM SIGSOFT Software Engineering Notes, Vol. 16, No. 3, Jul. 1991, pp 52-55.
-
P.T Cox, T. Pietrzykowski; "Using a Pictorial Representation To Combine Dataflow and object-orientation in a Language Independent Programming Mechanism"; Proceedings of the International Computer Science Conference, 1988, pp 695-704.
-
Alan M. Davis, Edward H. Bersoff, Edward R. Comer; "A Strategy for Comparing Alternative Software Development Life Cycle Models"; IEEE Transactions on Software Engineering, Vol 14 No 10, Oct. 1988, pp 1453-1461.
-
Mark Edel; "The Tinkertoy Graphical Programming Environment"; IEEE Transactions on Software Engineering, Vol 14 No 8, Aug. 1988, pp 1110-1115.
-
Ephraim P. Gilnert, Steven L. Tanimoto; "Pict: An Interactive Graphical Programming Environment"; IEEE Computer, Nov. 1984, pp 7-25.
-
David Harel, Hagi Lachover, Ammon Naamad, Amir Pnueli, Michal Politi, Rivi Sherman, Aharon Shtull-Trauring, Mark Trakhtenbrot; "STATEMATE: A Working Environment for the Development of Complex Reactive Systems"; IEEE Transactions on Software Engineering, Vol. 16, No. 4, 1990, pp 403-413.
-
Bertrand Ibrahim; "Software engineering techniques for CAL"; Education & Computing, Vol 5, pp 215-222, Elsevier Science Publishers, 1989.
-
Bertrand Ibrahim, Alain Aubord, Birgit Laustsen, Michael Tepper; "Courseware CAD"; WCCE/90, Conference Proceedings, pp. 383-389, North-Holland, 1990.
-
Bertrand Ibrahim; "Diagrammatic representation of data types and data manipulations in a combined data- and control-flow language"; IEEE International Symposium on Visual Languages, Halifax, Canada, Sep. 1998, pp. 262-269.
-
Robert J. K. Jacob; "A State Transition Diagram Language for Visual Programming"; IEEE Computer, Aug. 1985, pp 51-59.
-
Jean-Louis Léonhardt; "Final Report on Advanced Authoring Tools"; Delta Final Project Report Summary Delta-AAT-D1010, Mar. 1991.
-
Francesmary Modugno, Brad Myers; "Pursuit: Visual Programming in a Visual Domain"; Carnegie Mellon University, Technical report CMU-CS-94-109, Jan. 1994.
-
D. L. Parnas; "On the Use of Transition Diagrams in the Design of a User Interface for an Interactive Computer System"; Proceedings of the 24th National ACM Conference, 1969, pp 379-385.
-
Christian Pellegrini; "Un Système Interactif d'Aide à la Conception de Programmes"; Ph.D. Thesis No 1724, University of Geneva, Switzerland, 1975.
-
Georg Raeder; "A Survey of Current Graphical Programming Techniques"; IEEE Computer, Aug. 1985, pp 11-25.
-
C. V. Ramamoorthy, Vijay Garg, Atul Prakash; "Programming in the Large"; IEEE Transactions on Software Engineering, Vol SE-12 No 7, July 1986.
-
Bruce A. Sherwood, J. N. Sherwood; "The cT Language and its Uses: a Modern Programming Tool"; Proceedings of the Conference on Computers in Physics Instruction, North Carolina State University, Addison-Wesley, Aug. 1988.
-
Leonard L. Tripp; "A Survey of Graphical Notations for Program Design - An Update"; ACM Software Engineering Notes, vol 13 no 4, Oct. 1988, pp 39-44.
-
Anthony I. Wasserman; "Extending State Transition Diagrams for the Specification of Human-Computer Interaction"; IEEE Transactions on Software Engineering, Vol SE-11 No 8, Aug.1985, pp 699-713.
Site Hosting: Bronco