{kind=link}
{kind=link}
{kind=link}
1) use of the technology on a closed corpus of educational material, for the hypermedia and distance delivery capabilities of the web, on one hand, and
2) use of this technology on an organized structure of links for an open corpus of material that was not necessarily meant initially for pedagogical use, but which can be "redirected" and exploited in a guided exploratory pedagogy approach.
These two axes are not antagonistic but can be alternatively or complementarily followed.
In this paper, we will describe the main features of WWW, then analyze those features that are most interesting for educational purposes, and finally show an example of a sophisticated pedagogical use of the web. Through this example, we will show how educational programs can be executed remotely through WWW, thus making use of all the interesting features of this tool, i.e. hypermedia and remote access, without giving up on those features that make tutorials "intelligent", i.e. maintain a profile of the user and adapt the behavior of the program to the abilities of the learner.
While describing technical solutions which make such pedagogical use possible, this paper will also indicate limitations that WWW imposes on the courseware designers and how these limitations may impact on the pedagogical quality of the material. By this balanced presentation of strength and limitations, we hope to show realistically the enormous educational potential of this tool.
Table 1: NSFNet backbone statistics (in Megabytes)
| Month | total | ftp-data | WWW | Gopher |
|---|---|---|---|---|
| Jan. 94 | 10'294'076.39 | 4'243'108.44 | 269'129.08 | 374'680.91 |
| Feb. 94 | 11'415'444.42 | 4'482'332.17 | 347'503.52 | 396'066.06 |
| Mar. 94 | 14'024'028.12 | 5'172'361.87 | 518'083.62 | 480'689.69 |
| Apr. 94 | 14'312'300.66 | 5'147'611.59 | 671'950.15 | 517'625.28 |
| May 94 | 15'457'170.81 | 5'643'879.59 | 799'162.73 | 555'707.65 |
| June 94 | 15'350'480.26 | 5'406'765.55 | 946'538.67 | 567'478.66 |
| Jul. 94 | 15'947'658.87 | 5'389'933.69 | 1'056'081.23 | 555'088.51 |
| Aug. 94 | 16'541'742.15 | 5'829'173.74 | 1'311'822.50 | 651'846.26 |
| Sep. 94 | 18'622'407.09 | 6'047'578.39 | 1'593'463.75 | 751'454.67 |
| Oct. 94 | 21'197'056.32 | 7'030'428.06 | 2'152'956.67 | 864'259.38 |
Initially, WWW was meant to facilitate collaboration
among physicists, but it quickly caught on in the computer
science community and the scientific community in
general. It is getting more widespread every day, to the
point that the network traffic for the WWW has increased
seven-fold between January and October 1994 (see Table
2), reaching more than 10 per cent of the overall Internet
traffic (see Table 3).
Table 2: traffic increase between Jan. and Oct. 1994
| total | ftp-data | WWW | Gopher |
|---|---|---|---|
| 105.92% | 65.69% | 699.97% | 130.67% |
Table 3: WWW traffic in % of total traffic
| Jan. | Feb. | Mar. | Apr. | May | Jun. | Jul. | Aug. | Sep. | Oct. |
|---|---|---|---|---|---|---|---|---|---|
| 2.6% | 3.0% | 3.7% | 4.7% | 5.2% | 6.2% | 6.6% | 7.9% | 8.6% | 10.2% |
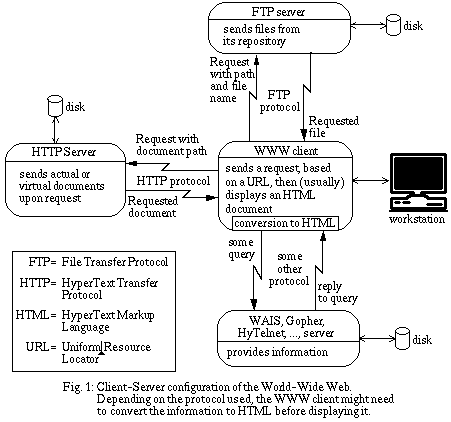
A viewer is a program that can send requests for documents, based on users' interactions, and display these documents on the computer screen. Mosaic [2] is probably the most well known WWW viewer, but many other WWW viewers are available for many different platforms, including simple VT100 terminals connected through a phone line to a computer that has access to the Internet.
The most common configuration is to have, on the client side, a viewing program that will display documents on a computer screen, and on the server side, an HTTP server program that will send documents stored in simple ASCII text files. These documents will usually be in HTML syntax, which is a device-independent markup language somewhat similar to, but simpler than, Latex. All the various viewers adapt the display of the documents to the capabilities of the computer or terminal screen. If a document includes a reference to another document, the viewer will show the "hyperlink" in various ways, depending on the capabilities of the screen.
The viewing program is usually knowledgeable enough about the various Internet protocols to send a query in the appropriate format to various sorts of servers, and to transform the server reply back into HTML. As we said earlier, WWW is based on a uniform naming scheme for Internet resources, whether these resources are simple files, databases or other computing facilities. The scheme is based on Uniform Resource Locators (URL) consisting of three main fields tied together with the following syntax:
protocol_name://Internet_address_of_server_host/pathwhere "path" is either the full path of a document in the server storage space, or a query to a database server, or some information allowing the server to locate unambiguously a resource it has access to.
Documents sent by an HTTP server are not necessarily text files with HTML syntax. Documents are typed and, depending on their type, the viewing program might either display them directly, or spawn an external viewer to handle them. For instance, Postscript files will be displayed by an external program that knows how to display Postscript files on the client machine. There are many different predefined document types, and additional types can be defined, along with the name of the (viewing) programs that will know how to handle them.
HTML documents can not only contain text, but also icons and even full-size images that will all be displayed together in the same window. Of course, viewers that cannot handle graphics like those for VT100 terminals, will only display the textual part of a document and give, whenever possible, a hint about the graphics that could not be displayed. Thankfully, graphics-capable viewers are the vast majority and most WWW users can benefit from its multimedia capabilities.
Any component in an HTML document -a portion of text, an icon or an image- can hold a link to another document, via a URL reference, allowing information providers to build complete hypermedia structures that can be browsed through very easily. On a mouse-based system, the user just needs to "click" with the mouse on the component holding the link and the viewer will automatically retrieve the referenced document and either display it directly if it is an HTML document, otherwise it will use an external viewer. For the moment, documents that are displayed by external viewers are leaf nodes in the hyperstructure, that is, they cannot hold links to other documents. But extensions are planned that will enable external viewers to pass references along for the main WWW viewer to follow.
A new feature that has been added recently to HTML is the possibility of including, in a document, input fields that the reader can fill out and the contents of which will be transmitted when the reader pushes a "submit" button. This fill-out form capability has been essential in allowing new uses of the web, where the user can be more active than just clicking on sensitive areas of a document.
An interesting aspect of the World-Wide Web is that it is very easy to become an information provider. Many public- domain HTTP server programs are available in executable format, and it is merely a matter of downloading one of them on the machine that will become the server, then setting up the configuration to gain potential visibility all over the Internet. The rest is then a matter of publicizing the address of one's server and the resources that it has. As we mentioned earlier, it is possible to provide information other than HTML documents. An HTTP server can be configured to invoke external programs or shell scripts to provide virtual documents that will be composed in response to the client's request. These external programs can have many purposes, like querying a database or providing a gateway to some online service, and will usually use the "path" part of the URL to parametrize their action. They have to return their results in HTML syntax, as a virtual document.
There are however structured ways in which WWW can be used for education. Two main approaches come to mind: on one hand, using the technology on a closed corpus of educational material, mostly for the hypermedia and distance delivery capabilities of WWW and, on the other hand, using the technology to access, in a structured way, an open corpus of material that was not necessarily meant initially to be used for specific educational purposes.
One characteristic of WWW that can appear as a limitation is the fact that the HTTP protocol is stateless, that is, there is no direct relationship of any kind between two consecutive requests to the same server, even if the queries come from the same user. The server treats every request it receives independently from any other request it received in the past or that it will receive in the future. This statelessness allows the HTTP server software to impose very little overhead on the server machine, and keeps the protocol between the client and server very simple.
However, good educational material should take into account the background of each learner to tailor its behavior to the learner's capabilities and past history, and to provide appropriate remediation to learners who experience difficulties with some concepts. To achieve this, the educational software has to keep track of the users' states and actions, which seems to contradict the statelessness of WWW. The solution we developed to overcome this difficulty [1] has been to combine the fill-out form capability with the possibility for the HTTP server to execute external programs or shell scripts in response to a query.
Normally, when the HTTP server executes an external program or shell script, it waits until the program is finished to send the program's output as a virtual HTML document. In our case [3], to maintain a state between consecutive requests, the external shell script spawns a child process that will continue executing during the whole educational sequence. The output of the child process is passed to the HTTP server as a virtual HTML document. The hyper-links embedded in this document contain the process Id of the child process. With this information, the shell script invoked by the HTTP server on a later request can reconnect to the spawned child process and pass it the rest of the request data that will contain information provided by the learner. This mechanism is described in Fig. 2.
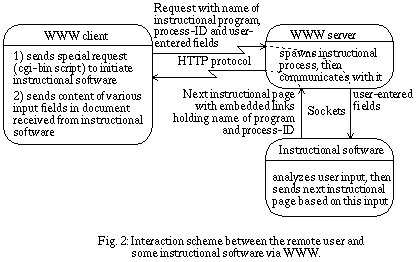
The approach we have just described has its advantages and its drawbacks. Among the advantages we find the portability achieved by using HTML for the spawned process output. Whatever the machine the user is working on, the viewer should be able to handle HTML documents and thus be able to display the output of the educational process, regardless of the hardware of the machine. There is therefore only one executable version of the courseware, that resides on the server machine. As a consequence, anybody can engage very simply in the educational process, from anywhere in the (Internet) world, at any time, without any bootstrapping procedure. One drawback is that this server machine can become overloaded and thus unable to server new users. Another drawback is that the user interactions and the program output are limited by the HTML syntax.
Another approach to the closed corpus option is to define a new document type and have a special dedicated viewer handle the "document" sent by the HTTP server. This viewer can be an interpreter for some special purpose language and it will use the document sent by the server as a program to interpret/execute on the client machine, thus removing the load from the server. This external viewer can send a specific system signal to the main WWW viewer to tell it to display a new document, the URL of which has been put in a temporary file. When used in combination with fill-out forms, this allows bidirectional communication between the main WWW viewer and the external viewer that are both running on the same client machine. The main advantage of this approach is that it can potentially use all the graphical and computational capabilities of the client machine, thus resulting in more powerful user interfaces and faster response times. The drawbacks are that one needs to have a dedicated viewer on the client machine (this viewer has to be downloaded by the users/learners before they can start the educational process, or it has to be pre- installed by the teacher or the local system manager) and that a different executable version of the interpreter has to be produced for every different kind of hardware that the learners can potentially use. Another possible drawback could be related to security issues if the interpreter can potentially execute instructions that would harm the local computer environment (software viruses).
Given its gigantic size, this ocean of information has to be harnessed to make it manageable and useful to users and learners. In this regard, WWW appears to be very useful in that its network-based hypertextual capabilities make it very appropriate to organize into a hierarchy this huge volume. CERN - Centre Européen de Recherche Nucléaire (European Center for Nuclear Research), birthplace of the World-Wide Web - has started a very interesting project called the WWW Virtual Library. Its purpose is to create a distributed catalogue of all the Internet resources accessible via WWW. It is maintained on a voluntary basis by people who are specialists in a specific domain and who are willing to share and maintain a document, or a hierarchy of documents, that reflect a certain structure of their domain, giving access to all the major Internet-accessible resources that they are aware of. The subjects of the WWW Virtual Library range over a very wide spectrum, covering most regular subjects of study, as well as recreational subjects or more esoteric ones like "Paranormal Phenomena" or UFOs.
Electronic journals and online magazines also constitute interesting sources of information that are probably going to develop and grow as people get more accustomed to the electronic media.
As useful as they may be for researchers or post-graduate students, these structuring resources are probably not directly usable as is for more basic educational purposes. They are nevertheless a good example of what can be done to present a subject to people who want to learn about it. One can easily imagine developing more elaborate structural documents that will guide learners in their exploration of a subject domain. The educational material would thus consist of a combination of explanatory text, pointers to more in-depth material publicly available on the Internet and, possibly, some features of the closed corpus approach by which the learner could be evaluated and proposed complementary or remedial material.
 .
.
 Bertrand Ibrahim
Bertrand Ibrahim
Site Hosting: Bronco