 this document requires a viewer that implements the HTML 3.2
"table" facility. For those readers who are not using a
"table-capable" viewer, links to GIF images of the tables are provided.
this document requires a viewer that implements the HTML 3.2
"table" facility. For those readers who are not using a
"table-capable" viewer, links to GIF images of the tables are provided.
this document requires a viewer that implements the HTML 3.2
"table" facility. For those readers who are not using a
"table-capable" viewer, links to GIF images of the tables are provided.
In spite of the lack of software specially designed for reuse, there is a lot of software available that was not specially designed with reuse in mind but that can be reused. Source code is available in different programming languages and different specification languages/formalisms are used for other development products. The documentation in natural language that is normally available with these products provides a uniform description of the software artifacts that can be used to classify and retrieve them.
Most on-line information systems currently offer some searching capability, but this tends to be very primitive (e.g. `man -k', WAIS, Archie, Gopher/Veronica, WWW). More precision is needed for the identification of software artifacts.
Information retrieval techniques have been frequently used to construct and evaluate software retrieval systems and following the research in that area, earlier reuse systems were keyword-based. In these systems, catalogues are usually constructed manually and components are retrieved by specifying a set of keywords under a software classification scheme, using either a free vocabulary or a controlled one. But constructing software libraries by indexing software components manually is difficult and expensive. Automatic indexing is required to turn software retrieval systems costeffective.
On the other hand, the effectiveness of traditional keyword based retrieval systems is limited by the expertise of users as well as by the size of the software libraries. Moreover, the effectiveness of these systems is limited by the so-called "keyword barrier", i.e. the systems are unable to improve retrieval effectiveness beyond a certain performance threshold [14]. This situation is particularly critical in software retrieval where users require high precision, i.e. they expect to retrieve only the best components for reuse, avoiding to have to select the best one from a list containing many irrelevant components.
The availability of machine-readable dictionaries and developed techniques for language analysis have made possible the application of natural language processing techniques to information retrieval systems [2] [3] [11] [12] [18] [21]. The main purpose of this work is to experiment with these techniques in the domain of software descriptions and evaluate their potentiality to construct more effective reuse systems.
This paper describes an approach for automatic indexing of software components from their descriptions in natural language. Some results from an initial experiment with the classification system are also discussed. The classification approach is being used in ROSA (Reuse Of Software Artifacts), a software reuse system [6] [7] [8] [9] [10] that aims at being cost-effective, domain independent and providing good retrieval performance. The retrieval mechanism of ROSA is only briefly described in this paper. A detailed description of this mechanism with the similarity measures applied on retrieval operations is done in [9]. Some results on retrieval evaluation are also discussed in [10].
The paper is organized as follows. Section 2 summarizes
main approaches for software classification. Section 3
outlines the main mechanisms in the current version of
ROSA. Section 4 describes the classification formalism
used to identify, in a software description, the knowledge
needed to catalogue the component in a library. Section 5
introduces the defined mechanisms for the analysis of both
queries and component descriptions (morpholexical, syntactic
and semantic analysis) and the semantic structure of
the Frame Base. Section 6 discusses the results of an initial
experiment with the classification system and section 7 introduces
some results on retrieval evaluation. Section 8
concludes the paper with some remarks on retrieval results
[10] and on the advantages and limitations of the proposed
approach.
2 Classification of software
This section summarizes major approaches for software
classification: the approaches that propose a classification
scheme according to which software artifacts are catalogued
in a software base by a manual indexing procedure
[17][22][24] and more recent proposals that take advantage
of the lexical, syntactic and semantic information available
in the natural language documentation of software artifacts
to both improve retrieval effectiveness and support the automatic
indexing of components [1][13][16].
2.1 Manual indexing
Wood and Sommerville [24] propose a frame-based
software component catalogue, that aims at capturing the
meaning of software components. The catalogue consists of
a frame for the basic function that a software component
performs, with slots for the objects manipulated by the component.
Prieto-Diaz [17] proposes a faceted classification scheme for cataloguing software components. This scheme has also been adopted by other reuse proposals, like the REBOOT project [20]. The scheme uses facets as descriptors of software components. These facets have a meaning similar to some semantic cases defined in this work. The scheme consists of four facets: the function performed by the component, the object manipulated by the function, the data structure where the function takes place (medium or location) , and the system to which the function belongs.
NLH/E (Natural Language Help/English) [22] is a question-answering system that accepts queries in English. The authors propose a frame-based software component catalogue for software components, organized as a case grammar. The catalogue is created manually but queries are parsed using the case grammar. The catalogue is specific to the Common Lisp domain.
PROTEUS [5] is a software reuse system that supports different classification methods for software components (simple keyword-based, faceted, enumerated graph and attribute value) in order to do comparative empirical evaluation of those methods.
2.2 Automatic indexing
Systems that provide automatic indexing of software
components can be classified in two basic groups: systems
that work only at the lexical level [13] and systems that include
syntactic and semantic analysis of software descriptions
[1][16].
Lexical processing. The GURU system [13] classifies software components according to attributes automatically extracted from their natural language documentation by using an indexing scheme based on the notions of lexical affinity and quantity of information. The retrieval system accepts queries in free style natural language and the same technique used to index software components is applied to queries. Even without attempting any understanding of the descriptions and without using any kind of syntactic and semantic knowledge, the system exhibits better precision than single keyword-based systems.
Syntactic and semantic processing. These systems make some kind of syntactic and semantic analysis of natural language specifications without pretending to do a complete understanding of the descriptions. They are based upon a knowledge base which stores semantic information about the application domain and about natural language itself. These systems appear more powerful than traditional keyword retrieval systems but they usually require enormous human resources because knowledge bases are created manually for each application domain. Some of the systems that follow this approach are described below.
LaSSIE (Large Software System Information Environment) [1] is composed of a knowledge base, a semantic analysis algorithm based on formal inference and a user interface incorporating a graphical browser and a natural language parser. LaSSIE helps programmers in searching useful information about a large software system and also supports the retrieval of components for reuse. The construction of the knowledge base is currently a manual process and future directions of the project point to the definition of knowledge acquisition mechanisms to automate that process.
Nie [16] proposes a software retrieval system for components
documented in French. Both input sentences and
software descriptions are parsed using a semantic grammar.
A knowledge base for a restricted application domain has
been created to assist the parsing process. Knowledge consists
of a set of classes modelling data and operations in the
domain and a set of relationships among concepts in the
classes.
3 Overview of ROSA
The current version of the ROSA reuse system consists
of a classification mechanism and a retrieval mechanism.
The classification system catalogues the software components in a software base through their descriptions in natural language. An acquisition mechanism automatically extracts from software descriptions the knowledge needed to catalogue them in the software base. The system extracts lexical, syntactic and semantic information and this knowledge is used to create a frame-based internal representation for the software component.
The interpretation mechanism used for the analysis of a description does not pretend to understand the meaning of a description. It attempts to automatically acquire enough information to construct useful indexing units for software components. Syntactic and semantic analysis of descriptions follow the rules of a classification formalism. The formalism consists of a case system, constraints and heuristics to perform the translation of the description into an internal representation.
Public domain lexicons are used to get lexical and semantic information needed during the parsing process. The WordNet [15] lexicon is used to obtain morphological information, grammatical categories of terms and lexical relationships between terms.
The Software base is a base of frames where each software component has a set of associated frames containing the internal representation of its description along with other information associated to the component (source code, executable examples, reuse attributes, etc).
A similar analysis mechanism to the one applied to software descriptions is used to map a query in free text to a frame-based internal representation. The retrieval system [9][10] looks for and selects components from the Software base, based on the closeness between the frames associated to the query and to the software descriptions. Closeness measures [9] are derived from the semantic formalism and from a conceptual distance measure between the terms in frames under comparison. Software components are scored according to their closeness value with the user query. The ones with a score higher than a controlled threshold become the retrieved candidates.
As a first step, the system deals with imperative sentences
for both queries and software descriptions. Imperative
sentences describe simple actions that are performed by
a software component, the object manipulated by the action,
the manner by which the action is performed and other semantic
information related to the action.
4 The classification formalism
This section describes the formalism used to represent
software descriptions. Through a case system for simple imperative
sentences, the formalism establishes the rules to
generate the internal representation of both queries and natural
language descriptions of software components. The
formalism is inspired by the linguistic case theory of Fillmore
[4].
4.1 The case system
Definition 1 A case system for imperative sentences
The case system for an imperative sentence consists basically of a sequence of one or more semantic cases:

where:
C = {j | j is a semantic case}
cj = the term in the sentence associated with the semantic
case `j'
Semantic cases are associated to some syntactic compounds of an imperative sentence. An imperative sentence consists of a verb (representing an action) followed by a noun phrase (representing the direct object of the action) and perhaps some embedded prepositional phrases. For instance, the sentence `search a file for a string' consists of the verb `search', in the infinitive form, followed by the noun phrase `a file', which represents the object manipulated by the action, and followed by the prepositional phrase `for a string', which represents the goal of the `search' action. In the example, the semantic cases `Action', `Location' and `Goal' are respectively associated to the verb, direct object and prepositional phrase of the sentence:
`search a file for a string' --> cAction + cLocation + cGoal
Definition 2 Semantic cases
Semantic cases show how noun phrases are semantically related to the verb in a sentence. For instance, in the sentence `search a file for a string', the semantic case `Goal' associated to the noun phrase `for a string' shows the target of the action `search'. We have defined a basic set of semantic cases for software descriptions by analyzing the short descriptions of Unix commands in manual pages (Table 1). These semantic cases describe the basic functionality of the component (the action, the target of the action, the medium or location, the mode by which the action is performed, etc.).
| Semantic case | Description |
|---|---|
| Action | The main verb in an imperative sentence |
| Agent | The software component that implements an action (implicit) |
| Comparison | The entity compared with the main object of an action |
| Condition | The premise upon which an action is performed |
| Destination | The destination of the object |
| Duration | How long an action lasts |
| Goal | The manipulated object, the target or result of an action |
| Instrument | The entity with which an action is performed |
| Location | Where an action occurs or the entity manipulated | by an action
| Manner | The mode by which an action is performed |
| Purpose | The reason for an action |
| Source | The origin of the object manipulated by an action |
| Time | When an action occurs |
Definition 3 Case generators
A semantic case consists either of a verb (the `Action' semantic case) or a case generator (possibly omitted) followed by a noun phrase (the "Purpose" semantic case is an exception; it consists of a case generator followed by a verbal phrase):
ci --> (Case generator) + Noun phrase
A case generator reveals the presence of a particular semantic case in a sentence. Case generators are mainly prepositions. For instance, in the sentence `search a file for a string', the preposition `for' in the prepositional phrase `for a string' suggests the `Goal' semantic case.
Table 2 shows some generators of the semantic cases considered in this work. They have been identified by analysing the short descriptions in manual pages of Unix commands; the meaning of prepositions and the relationships of the prepositions with the defined semantic cases. Some case generators suggest more than one semantic case. For instance, the preposition `for' suggests all three semantic cases `Goal', `Purpose' and `Duration'. The semantic analysis of descriptions tries to disambiguate these different interpretations by applying a set of heuristics (based both on syntactic and semantic knowledge) to the associated prepositional phrase that follows in the sentence.
| Semantic case | Case generator |
|---|---|
| Comparison | as, between, like, with |
| Condition | as, at, except, how, unless, until |
| Destination | to |
| Duration | during, for, through |
| Goal | for, to |
| Instrument | `by using', with, using |
| Location | at, in, into, on, through, within |
| Manner | by |
| Purpose | for, to |
| Source | from |
| Time | at, in, into, on, through |
Definition 4 Case system constraints and heuristics
The following constraints and heuristics govern the case system. They state syntactic and semantic rules to identify semantic cases in a sentence.
The purpose of morpholexical analysis is to process the individual words in a sentence to recognize their standard forms (e.g. `search' as the standard form of `searching'), their grammatical categories (verb, noun, adjective, adverb) , and their semantic relationships with other words in a lexicon (like synonyms, hypernyms and hyponyms). Morpholexical analysis also performs the processing of collocations and idioms, i.e. where two or more individual words are used in usual association (multi-word lexical entries).
Two semantic relations between terms are currently considered: synonymy and hyponymy/hypernymy. The predicate synonym(x,y,c) means that the term `y' is a synonym of the term `x' in the `c' lexical category (e.g. synonym (`computer', `data processor', noun)). The predicate hyponym(x,y,d,c) means that the term `y' is an hyponym (a specialization) of the term `x' at a d-distance in a thesaurus in the `c' lexical category (e.g. hyponym (`computer', `PC', 1, noun)). The predicate hypernym(x,y,d,c) means that the term `y' is an hypernym (a generalization) of the term `x' at a d-distance in a thesaurus in the `c' lexical category (e.g.hypernym (`computer', `machine', 1, noun)).
Just after morpholexical analysis, both syntactic and semantic analysis of software descriptions are performed by using a definite clause grammar, supporting the case system. The defined grammar implements a subset of the grammar rules for imperative sentences in English [23]. This parsing phase generates a set of derivation trees, corresponding to the different syntactic interpretations of the description, with the semantic constraints imposed by the case system.
Further semantic analysis of the generated derivation trees is performed to apply some constraints of the case system and some heuristics to disambiguate different interpretations of a description. A set of semantic structures, used as the internal representation of the description is generated as a result of this analysis phase.
These semantic structures are created according to the classification scheme of Figure 1. The classification scheme consists of a hierarchical structure of generic frames (`IS-A-KIND-OF' relationship). Frames that are instances of these generic frames (`IS-A' relationship) implement the indexing units of software descriptions.
Case_frame --> FRAME Frame_name Hierarchical_link CASES Case_list.
Hierarchical_link --> IS_A Frame_name | IS_A_KIND_OF Frame_name
Case_list --> Case (Case_list)
Case --> Case_name Facet
Case_name --> Semantic_case_name | Other_case_name
Semantic_case_name --> Action | Agent | Comparison | Condition |
Destination | Duration | Goal | Instrument |
Location | Manner | Purpose | Source | Time
Other_case_name --> Modifier | Head | Adjective_modifier |
Participle_modifier | Noun_modifier
Facet --> VALUE Value | DOMAIN Frame_name | CATEGORY Lexical_category
Value --> string | Frame_name
Lexical_category --> verb | adj | noun | adv | component_id | text.
Frame_name --> string.
Figure 1 - A classification scheme for software artifacts
Major generic frames for the Frame Base are shown in Figure 2. They model semantic structures associated to verb phrases, noun phrases and the information associated to software components, like name, description, source code, executable examples, etc.
FRAME verb_phrase IS_A_KIND_OF root_frame
CASES
Action CATEGORY verb
Agent DOMAIN component
Comparison DOMAIN noun_phrase
Condition DOMAIN noun_phrase
Destination DOMAIN noun_phrase
Duration DOMAIN noun_phrase
Goal DOMAIN noun_phrase
Instrument DOMAIN noun_phrase
Location DOMAIN noun_phrase
Manner DOMAIN noun_phrase
Purpose DOMAIN verb_phrase
Source DOMAIN noun_phrase
Time DOMAIN noun_phrase.
FRAME noun_phrase IS_A_KIND_OF root_frame
CASES
Adjective_modifier CATEGORY adj
Participle_modifier CATEGORY verb
Noun_modifier CATEGORY noun
Head CATEGORY noun.
FRAME component IS_A_KIND_OF root_frame
CASES
Name CATEGORY component_id
Description CATEGORY text
.
. {Other information associated to the component,
. e.g. source code, executable examples, reuse
attributes, etc}
Figure 2 - Some generic frames of the Frame Base
Semantic cases are represented as slots in the frames. `Facets' are associated to each slot in a frame, describing either the value of the case or the name of the frame where the value is instantiated (`value' facet); the type of the frame that describes its internal structure (`domain' facet) or the lexical category of the case (`category' facet). For instance, the `Location' slot in the verb phrase frame has a `domain' facet indicating that its constituents are described in a frame of type `noun phrase'.
Through a parsing process, the interpretation mechanism maps the verb, the direct object and each prepositional phrase in a sentence into a semantic case, based on both syntactic features and identified case generators.
Some case generators suggest more than one semantic case. For instance, the preposition `for' suggests all the semantic cases `Goal', `Purpose' and `Duration'. Some interpretations are disambiguated at the syntactic level (like `Purpose'); the other ones at the semantic level by applying a set of heuristics to the corresponding prepositional phrase in the sentence. For instance, the rule:
Duration(noun_phrase) --> hypernym(noun_phrase, `time period').
states a precondition for the `Duration' semantic case: the term in the `Duration' semantic case must be a specialization of the term `time period'.
Figure 3 shows the semantic structures generated for the short description of the grep family of UNIX commands, `search a file for a string or regular expression'.
frame('grep_verb_phrase_15',IS_A,verb_phrase).
case('grep_verb_phrase_15',agent,VALUE,'grep_component_15').
case('grep_verb_phrase_15',action,VALUE,'search').
case('grep_verb_phrase_15',location,VALUE,'grep_noun_phrase_30').
case('grep_verb_phrase_15',goal,VALUE,'grep_noun_phrase_31').
frame('grep_component_15',IS_A,component).
case('grep_component_15',name,VALUE,'grep').
case('grep_component_15',description,VALUE
,'search a file for a string or regular expression ').
frame('grep_noun_phrase_30',IS_A,noun_phrase).
case('grep_noun_phrase_30',head,VALUE,'file').
frame('grep_noun_phrase_31',IS_A,noun_phrase).
case('grep_noun_phrase_31',adj_modifier,VALUE,'regular').
case('grep_noun_phrase_31',head,VALUE,'expression').
frame('grep_verb_phrase_16',IS_A,verb_phrase).
case('grep_verb_phrase_16',agent,VALUE,'grep_component_15').
case('grep_verb_phrase_16',action,VALUE,'search').
case('grep_verb_phrase_16',location,VALUE,'grep_noun_phrase_30').
case('grep_verb_phrase_16',goal,VALUE,'grep_noun_phrase_33').
frame('grep_noun_phrase_33',IS_A,noun_phrase).
case('grep_noun_phrase_33',noun_modifier,VALUE,'regular').
case('grep_noun_phrase_33',head,VALUE,'expression').
frame('grep_verb_phrase_17',IS_A,verb_phrase).
case('grep_verb_phrase_17',agent,VALUE,'grep_component_15').
case('grep_verb_phrase_17',action,VALUE,'search').
case('grep_verb_phrase_17',location,VALUE,'grep_noun_phrase_30').
case('grep_verb_phrase_17',goal,VALUE,'grep_noun_phrase_35').
frame('grep_noun_phrase_35',IS_A,noun_phrase).
case('grep_noun_phrase_35',noun_modifier,VALUE,'string').
case('grep_noun_phrase_35',head,VALUE,'expression').
frame('grep_verb_phrase_23',IS_A,verb_phrase).
case('grep_verb_phrase_23',agent,VALUE,'grep_component_15').
case('grep_verb_phrase_23',action,VALUE,'search').
case('grep_verb_phrase_23',location,VALUE,'grep_noun_phrase_30').
case('grep_verb_phrase_23',goal,VALUE,'grep_noun_phrase_47').
frame('grep_noun_phrase_47',IS_A,noun_phrase).
case('grep_noun_phrase_47',head,VALUE,'string').
Figure 3 - The internal representation of the description
`search a file for a string or regular expression'
Note that the discontinuity in frame numbering is due to the frames that have been discarded by the disambiguation of the semantic cases that appear in the sentence. On the other hand, the ambiguity introduced by the `or' conjunction remains, producing the following alternative interpretations for the description:
Ambiguity is also introduced by the word `regular' which is both an adjective and a noun.
6 A classification experiment
A first prototype, implementing the basic functions of
the classification system was constructed in BIMprolog on
a SUN platform. Using this prototype, an initial experiment
to evaluate the effectiveness of the classification mechanism
has been conducted.
The experiment aimed at measuring, among others:
Morpholexical analysis. Figure 4 shows some results of the morpholexical analysis phase. 52% of the descriptions were accepted in this phase. These results were expected, given both the experimental state of the WordNet dictionary and the use of only one lexicon in the experiment.

Figure 4 - Morpholexical analysis results and reasons
for description rejection
The distribution of the reasons of rejection was the following:

Figure 5 - Syntactic analysis results and reason of rejection
Semantic analysis and frame construction. An average of 3.94 different interpretations by description were generated. It was also an expected result, considering that:
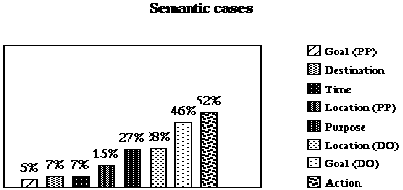
Figure 6 - Distribution of semantic cases found in verbal frames
Table 3 shows ROSA versus WAIS (Wide Area Information Server) retrieval effectiveness results computed with a test collection composed of 20 queries and a knowledge base containing 418 general purpose UNIX commands. The knowledge base was populated automatically through the classification mechanism described in this paper. Effectiveness was evaluated with the measures of recall and precision for ranked systems [19].
An important improvement for ROSA over WAIS of both precision (97.78%) and recall (32.62%) was observed.
| Recall Avg. | Precision Avg. | ||
|---|---|---|---|
| System | ROSA | 0.99 | 0.89 |
| WAIS | 0.73 | 0.45 | |
| Improvement ROSA over WAIS | +35.62 % | +97.78 % | |
8 Final remarks
A classification system for software artifacts has been
proposed. Through automatic indexing, the system aims at
reducing the cost of constructing software libraries. By
building software descriptors with lexical, syntactic and semantic
information extracted from software descriptions,
the system intends to provide good retrieval effectiveness.
Initial experimental results are encouraging. The classification approach is feasible and good retrieval effectiveness has been obtained. More experimentation is needed with larger corpora from divers software collections (e.g. Smalltalk library, ASSET collection, etc).
The NLP approach presents clear advantages from the point of view of costs over either manual indexing approaches or knowledge-based systems where knowledge bases are constructed manually. On the other hand, the retrieval effectiveness of our approach (and, in general, of all approaches for automatic indexing) depends not only on the effectiveness of the classification mechanism and retrieval similarity measures. It depends also on the quality of the software descriptions that are available. Bad descriptions will produce necessarily poor retrieval results. Descriptions describing components both in specificity and exhaustivity are needed to ensure a reasonable retrieval effectiveness.
Finally, the effectiveness of our approach depends on the quality of available dictionaries and thesauri. The WordNet lexicon has been very useful for our experiments. However, many word senses were not found as well as many semantic relationships between terms. Considering the large number of WordNet users we can expect that next releases will be more complete.
Site Hosting: Bronco