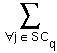 wj .
sc_closeness(cqj, cdj)
wj .
sc_closeness(cqj, cdj)
Two mechanisms of retrieval are proposed: a major retrieval mechanism, based on the similarities of the semantic structures, and a complementary mechanism, based on the matching of the noun phrases in the semantic structures.
The main retrieval mechanism provides good level of precision by reducing the number of irrelevant components that are retrieved. The retrieval is based on the detection of similar semantic structures, i.e. structures that share the same semantic cases and where there is some lexical relationships between the terms in the shared semantic cases.
Precision is controlled by basing the similarity analysis on the syntactic and semantic information available on the internal representation of both query and software descriptions; by scoring retrieved candidates and establishing a threshold for the required similarity. The threshold controls the number of retrieved documents and thus, the level of precision. Recall is increased by allowing partial matching of the semantic structures and considering synonyms, hyponyms and hypernyms of the terms in the semantic cases.
The complementary retrieval mechanism is based on the
simple matching of noun phrases identified in both query
and software descriptions. The approach is independent of
the semantic formalism we used in the main retrieval
mechanism but makes use both of the instance frames
associated to noun phrases and the closeness measures
defined for the main retrieval mechanism. This mechanism
has been defined to be used in comparative experimental
work with the main retrieval mechanism, to evaluate the
expected improvements in precision results, obtained
through the processing of semantic information, in relation
to the processing of mere syntactic information, through the
matching of noun phrases.
5.1 Similarity computation
Definition 1 Similarity between software descriptions
Similarity analysis is performed by comparing the internal
representation of the query with the ones of software
components descriptions in the Knowledge Base and
computing a similarity measure (Figure 1).
The function SCase (Fq, Fd), below measures the similarity between the frame Fq (the internal representation of the user query Q) and the frame Fd (the internal representation of a description D of a software component).
The measure is based both on the number of the semantic cases that have a match and on the closeness among the terms in the matched cases. Semantic cases are weighed by a factor (wj) that represents the relative importance of a semantic case in describing the functionality of the component. Closeness between semantic cases is a function of the conceptual distance between the terms in the semantic cases, according to its `domain' or `category' facet (single terms, noun phrases or verb phrases).
SCase (Fq, Fd) =
wj .
sc_closeness(cqj, cdj)
with,
wj = 1
where,
sc_closeness(cqj, cdj) =
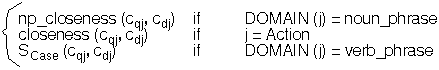
SCq = {j| j is a semantic case in the frame of Q}
cqj = the term of the semantic case `j' in
the frame of Q
cdj = the term of the semantic case `j' in
the frame of D
wj = the weight of the semantic case `j'
5.1.1 Closeness between single terms
Definition 2 Conceptual distance between single terms
The function dist(x,y) measures the conceptual distance
between the single terms or collocations `x' and `y', by
considering the distance of the terms in a lexicon, according
to the lexical relations of synonymy, hyponymy and
hypernymy described in section 4 (see example in
Table 1).
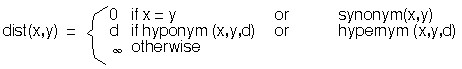
Definition 3 Closeness between single terms
The function closeness(x,y) measures the closeness
between the single terms or collocations `x' and `y'. The
function is inversely proportional to the conceptual
distance between the terms in
Definition 2 (see example in
Table 1).
Closeness(x,y) = vdist(x,y) with 0<v<1
| y | dist | closeness | remarks |
|---|---|---|---|
| v = 0.5 | |||
| 'PC' | 0 | 1 | synonym('personal computer', 'PC') |
| 'desktop computer' | 1 | 0.5 | hyponym('personal computer', 'desktop computer', 1) |
| 'laptop' | 2 | 0.25 | hyponym('personal computer', 'laptop', 2) |
| 'digital computer' | 1 | 0.5 | hypernym('personal computer', 'digital computer', 1) |
| 'computer' | 2 | 0.25 | hypernym('personal computer', 'computer', 2) |
5.1.2 Closeness between noun phrases
An instance of a noun phrase frame `x' consists of a head
`hx'(the main noun in the phrase) with
a list `Mx'of zero,
one or more modifiers (adjectives, nouns, participles).
Two assumptions are considered to compute the conceptual distance between noun phrases:

Definition 4 Conceptual distance between noun phrases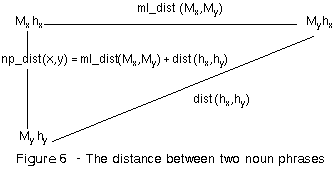
where,
x, y - noun phrase instance frames
hx, hy
- the head noun in frames x and y, respectively
Mx, My
- the list of modifiers of the frames x and y, respectively.
Definition 5 Conceptual distance between modifiers
The matrix M_DIST(Mx,My), m x m,
where m = max [length(Mx), length(My)],
defines the conceptual distance
between pairs of modifiers (mxi,
myj) from lists
Mx,
and My.
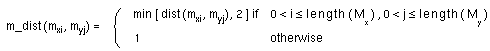
The conceptual distance between modifiers is computed by taking the minimum value of either the single term distance value between the modifiers, according to the measure in Definition 2, or a distance value of `2', according to the assumption that a modifier specializes a head noun. As illustrated in Figure 8, a maximum distance of `2' between the lists mx1 hx and my1 hx is obtained by considering that my1 hx is an specialization of hx and that hx is a generalization of mx1 hx. For instance,
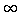 ,2) = 2
,2) = 2
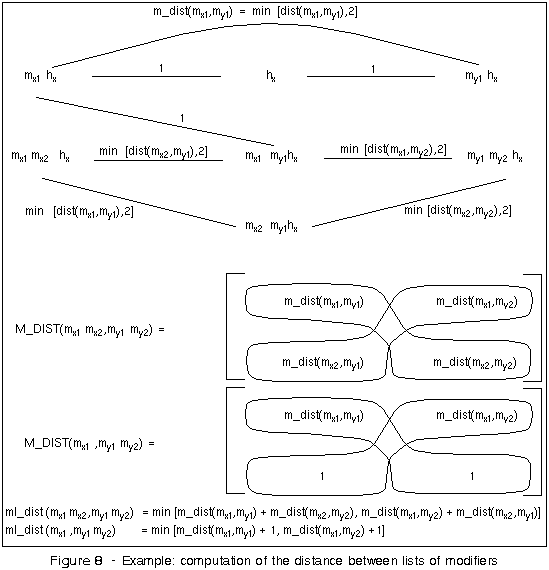
Definition 6 Conceptual distance between lists of modifiers
The function ml_dist (Mx,
My) computes the conceptual
distance between the lists of modifiers
Mx = mx1
mx2 ... mx.length(Mx)
and My = my1
my2 ...
my.length(My) (Figure 7).
The distance is computed by considering all the sets built
with pairs of different modifiers from
Mx and
My, and
taking the minimum sum of the distances between the pairs
of modifiers for all those sets. Figure 8 illustrates an
example of the computation of the conceptual distance
between the lists of modifiers
mx1
mx2
and my1
my2, as the
minimum value of the sums of the elements of the main and
secondary diagonal of the associated distance matrix.
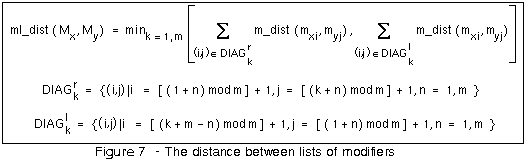
Definition 7 Closeness between noun phrases
The function np_closeness (x,y) measures the closeness
between two noun phrase frames `x' and `y'. The function
is inversely proportional to the conceptual distance
measure between noun phrase frames in Definition 4.
Closeness is computed by either considering or discarding
modifiers (u =1) in the noun phrase, to evaluate the relative
effects of modifiers in effectiveness results (see example in
Table 2).
np_closeness (x,y) =
uml_dist(Mx,My) . closeness (hx,
hy)
with 0 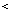 u
u
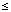 1
1
| x | np_cl. | np_cl. | remarks |
|---|---|---|---|
| u = 1, | u = 0.5, | ||
| v = 0.5 | v = 0.8 | ||
| 'computer program' | 1 | 1 | |
| 'program' | 1 | 0.5 | |
| 'machine program' | 1 | 0.5 | hyponym('machine', 'computer', 1) |
| 'PC software' | 0.5 | 0.4 | hypernym('PC', 'computer', 1), |
| hyponym('software', 'program', 1) | |||
| 'conference program' | 1 | 0.25 |
5.2 Noun phrase similarity
Definition 8 Similarity between descriptions by considering syntactic phrases
The function SPhrase (NPq,
NPd) measures the similarity
between the set
of noun phrases NPq in the frame
Fq, associated to
a user query Q and the set of noun phrases
NPd in the frame
Fd, associated to a description
D of a software component.
The similarity measure uses the closeness function in Definition 7 to compute the maximum closeness between each noun phrase in the query and the noun phrases in a software description. The average closeness value for all noun phrases in the query is then computed.
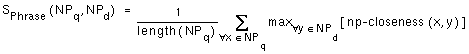
where
NPq = list of noun phrase instance frames of Q
NPd = list of noun phrase instance frames of D
6 Experimental comparison
Site Hosting: Bronco