 VP-SE Research Group (C)
VP-SE Research Group (C)
The effectiveness of keyword-based retrieval systems is limited by the so-called "keyword barrier" [19], i.e. these systems are unable to improve retrieval effectiveness beyond a certain performance threshold. This situation is particularly critical in software retrieval where users require high precision. Promoting software reuse in practice demands minimizing the effort of selecting a component from the list of retrieved ones and thus the list should contain only the best suited components to the user requirements.
Some interviews [1], conducted to discover user needs and attitudes toward reuse, show that users consider reuse worthwhile, but most of them expect more from application generators or from tools for automatic programming than from reuse systems like browsers or keyword-based systems. Users require more friendly and effective support for reuse.
Queries in natural language allow for improving the precision of retrieval systems. Precision can be improved by allowing queries with multiple words or phrases extracted from the natural language specifications of software components.
Users also prefer natural language interfaces to retrieval systems than keyword-based interfaces [1]. It seems more friendly for a user to say "(I want a component to) search a file for a string" than to think in proper keywords, corresponding classification schemes and boolean combination of keywords.
In information retrieval, some improvements on retrieval effectiveness have been obtained with multi-keyword systems, using statistical methods to index documents based on the multiple occurrence of keywords in a text. These improvements are not enough and current research [23] recognizes that some form of natural language processing should be necessary to increase the effectiveness in text retrieval and other text processing operations. Thus, most recent information retrieval systems incorporate natural language processing techniques and this experience seems to be useful for the design of software retrieval systems.
Natural language processing techniques have been applied in information retrieval systems mainly at the lexical, syntactic and semantic level. Experiments with pure lexical and syntactic techniques have shown poor results and thus many current approaches experiment with partial understanding of text through semantic analysis [19].
In this paper we introduce work in progress for a software reuse system that aims to provide high precision in retrieval by applying natural language processing techniques to both queries and natural language descriptions of software components. Additional support for application developers (for understanding and adapting software components) and for library managers (for creation, organization and reorganization of software components) is discussed elsewhere [9].
The paper is organized in the following way. Section 2 describes the general architecture of the retrieval system and the mechanisms defined to improve retrieval effectiveness through semantic processing of both queries and descriptions of software components. Section 3 introduces the principal features of a courseware development environment we will use to evaluate this reuse approach. Section 4 summarizes related work in the area of reuse systems and on the application of natural language processing techniques in information retrieval systems. Section 5 concludes the paper with some remarks on current and further research.
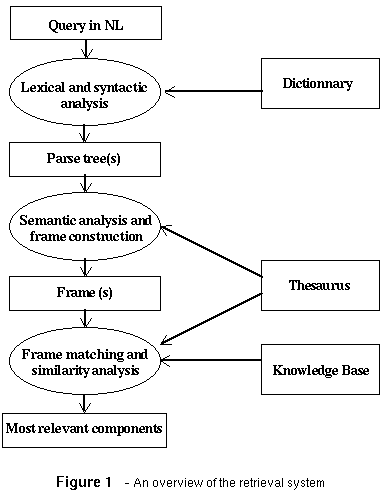
The retrieval system is composed of three subsystems (Figure 1): a lexical and syntactic analysis system, a semantic analysis system and a matching and similarity analysis system. The first system uses lexical processing techniques to identify the grammatical classes of the individual words that appear in the query by looking up a machine-readable dictionary. Syntactic processing is applied to determine the structure of the sentence. The semantic analysis system maps the grammatically parsed text into a knowledge representation formalism. We have chosen a frame-like formalism to represent the meaning of both the query and natural language descriptions of software components. The third system matches the semantic structure associated with a query against the ones associated to software components in a knowledge base. Partial matching is allowed and a similarity measure establishes which are the most relevant candidates to be retrieved. An independent thesaurus containing synonyms, generalizations and specializations of terms is used to disambiguate alternative interpretations of the query and to better match different formulations of the same query.
As a first step we deal with simple imperative sentences (verb phrases) for both queries and software component descriptions. A verb phrase consists of a verb with an embedded noun phrase and possibly some embedded prepositional phrases. A prepositional phrase consist of a preposition and a noun phrase. A basic noun phrase consist of a noun, along with a determiner and perhaps one or more adjectives. The sentences describe simple actions that have to be performed by the computer (e.g. "search a file for a string"). Support for more complex software descriptions will be considered on further research by extension of the semantic structure used in the internal representation of the software descriptions.
We expect to improve retrieval effectiveness by doing semantic processing of both queries and natural language specifications of existing components. However, we want to minimize the cost of generating semantic knowledge by introducing mechanisms for its automatic acquisition.
Semantic knowledge in knowledge bases is usually entered completely "by hand". For example, in systems that use semantic representations like case frames, the case frames used to parse natural language queries have to be created manually. Knowledge coded by hand is time-consuming, tedious and error- prone. We expect to automatically generate the semantic structures by automatically deriving thematic roles from the user input, using syntactic information and a set of heuristics.
Thematic roles show how noun phrases are semantically related to the verbs in a sentence. In the example taken from [27], the sentence "Robbie made coffee for Suzie with a percolator" contains four noun phrases, each one would be associated with a thematic role (Table 1): object (coffee), agent (Robbie), instrument (a percolator) and beneficiary (Suzie), indicating what was made, who made it, with what was it made and for whom was it made, respectively.
Noun phrase Thematic role
----------- -------------
Robbie agent
coffee object
Suzie beneficiary
a percolator instrument
Table 1 - Correspondence between noun phrases and thematic roles
Thematic Role Description
------------- ------------------------------------------------
AGENT The software component that implements an action
ACTION The verb in a sentence other than the "be-verb"
OBJECT The thing affected by an action
LOCATION Where an action occurs
TIME When an action occurs
PURPOSE The reason for an action
BENEFICIARY The thing for which an action is performed
DURATION How long an action occurs
INSTRUMENT The thing with which an action is performed
COMPARISON The thing compared with the object
DESTINATION The destination of the object
MANNER The mode by which an action is performed
SOURCE The origin of the object
CONDITION The premise upon which an action is performed
Table 2 - Thematic roles found in natural language descriptions of software components
Thematic role Prepositional triggers
------------- ----------------------
comparison between,as
location in,on,to,into,within
instrument with,by
destination to
beneficiary for,to
purpose to,for
manner as,in,by,with,at
source from
time at,when
duration for
condition until
Table 3 Thematic roles and prepositional triggers found in descriptions of Unix commands
CLASS Simple_Action
CASES
AGENT: string # software component name
ACTION: verb # the verb in the sentence
OBJECT: noun_phrase # the thing affected by the action
LOCATION: noun_phrase # where the action occurs
TIME: noun_phrase # when the action occurs
PURPOSE: noun_phrase # the reason for the action
BENEFICIARY: noun_phrase # the thing for which the action is performed
MANNER: noun_phrase # the mode by which the action is performed
.
.
.
CLASS PROCEDURES
Identify_thematic_role #create instances by identifying thematic roles
INSTANCE PROCEDURES
Find_synonyms # look for synonyms of a thematic role
Find_generalizations # look for generalizations of a thematic role
Find_specializations # look for specializations of a thematic role
.
.
.
Figure 2 - The generic definition of the semantic formalism
Figure 2 shows the frame-like semantic formalism we define to represent the meaning of either a
query or natural language descriptions of software components (simple actions). A set of slot_value pairs
provides the structural description of the unit, representing typical thematic roles found in descriptions
of software components. Procedural methods are associated to the class level, implementing methods for
automatic extraction of thematic roles from text input, and to the instance levels, implementing methods
for the matching of the semantic structures. In Figure 3, "Simple_Action_1" and "Simple_Action_2" are
instances created by the analysis of the sentences "search a file for a string" and "find references by
keyword", respectively.
SIMPLE_ACTION_1
AGENT "grep"
(a) ACTION "search"
OBJECT noun_phrase_1 # "a file"
BENEFICIARY noun_phrase_2 # "a string"
SIMPLE_ACTION_2
AGENT "man"
(b) ACTION "find"
OBJECT noun_phrase_3 # "reference pages"
MANNER noun_phrase_4 # "keyword"
The lesson designers draw the script of a lesson with a special purpose graphical editor. The lesson specifications are the input to an automatic programming system which produces the source code associated with the lessons in one of several commonly used general-purpose programming languages.The specification language combines a graphical formalism with natural language components and is specially attractive to courseware designers who are not programming experts. Given the semiformal aspect of the specification language, the automatic program generator that we have developed is not able to translate the whole specification into executable code. For this reason, we have included in our development environment a synchronous multi-window editor that simultaneously shows the specification while the automatically generated code is completed by hand. The natural language elements of the specification formalism are mainly directives to the coder and answer analysis criteria. The automatic program generator generates, for each directive, an external procedure and for each answer analysis criterion, a boolean function. The generator actually produces the declaration for these subprograms, but their bodies have to be written by a programmer.
The technique we have described in this paper will be used to increase the translation power of the IDEAL automatic program generator with a component reuse system. This reuse system will detect similarities between the natural language elements of a new specification and the description of existing code components. It will then suggest to the user all possible reuse opportunities.
Even though the indexing task on the faceted classification schema proposed by Prieto-Diaz [20] is not based on free-text analysis, the schema uses semantic information to describe software components similar to the one we associate to thematic roles. The schema consists of four facets: the function performed by the component, the objects manipulated by the function, the data structure where the function takes place (medium or location), and the system to which the function belongs. The three first facets are considered sufficient to describe the functionality of the component. For example, the following terms, corresponding to each one of the facets, describe a Unix component that "locate" (function facet), "line numbers" (objects facet) in a "file" (data structure facet) and are part of a "line editor" (system facet).
Relatively few software reuse systems take advantage of the rich source of conceptual information available in the natural language documentation of software components to improve retrieval effectiveness. Existing systems may be classified in two basic groups: free-text indexing reuse systems, and knowledge-based reuse systems.
The GURU system [17] classifies software components according to the attributes automatically extracted from their natural language documentation by using an indexing scheme based on the notions of lexical affinity and quantity of information. The retrieval system accepts queries in free style natural language and the same technique used to index software components is applied to queries. Even without attempting any understanding of the query and without using any kind of semantic knowledge, the system exhibits better precision than single keyword-based systems by constructing queries with pairs of words that occur in the text, according to the concept of lexical affinity.
The RSL (Reusable Software Library) [2] includes the RSL database and four subsystems: a library management system, a user query system, a software retrieval and evaluation subsystem and a computer- aided design system. The library management system, used to populate and maintain the software library, automatically scans source code files and extracts specially labelled comment statements with attributes such as keywords describing the functionality of components, author, date created, etc. The user query system has a natural language front-end and interacts with the user in order to refine the query and reduce the set of retrieved components. The software retrieval and evaluation subsystem retrieves and provides a score of software components through the specification of keywords that describe data-structure attributes. Finally, the computer-aided design system is used to include retrieved and selected components into an object-oriented design specification.
LaSSIE (Large Software System Information Environment) [4] is composed of a knowledge base, a semantic analysis algorithm based on formal inference and a user interface incorporating a graphical browser and a natural language parser. LaSSIE helps programmers in searching useful information about a large software system and also supports the retrieval of components for reuse. The construction of the knowledge base is currently a manual process and future directions of the project point to the definition of knowledge acquisition mechanisms in order to automate that process.
NLH/E (Natural Language Help/English) [29] is a question-answering system that accepts queries in English. The evolution of NLH/E towards an expert system for reuse is one of the project goals. The system consists of a caseframe parser, a thesaurus and a caseframe grammar. The thesaurus and the grammar are specific to the Common Lisp domain. The input is restricted to imperative sentences or nominal phrases. Input sentences are matched against caseframes in a knowledge base. These frames are created manually. The parser simply returns the tree of matched caseframes. If there is no possible match that consumes all input, the parser returns the "best" matches, i.e. those that account for most of the input.
The availability of machine readable dictionaries has allowed the use of lexical processing techniques in information retrieval. Stemming is a lexical technique frequently used. A stemming algorithm uses morphological information to remove suffixes from words, thus reducing variations on a root word to a single form or stem.
Machine-readable dictionaries have also been used in information retrieval to index text and queries by word senses instead of words themselves. These approaches aim to increase the precision in retrieval by providing a solution to the polysemy phenomenon, i.e. the fact that words have multiple meanings. Polysemy reduces precision because the words used to match relevant documents may have other meanings that can be present in irrelevant documents. The dictionary provides a definition for each sense of a word and the system tries to infer which sense is most likely to be correct by looking for confirmation of this evidence in the context in which the word appears. Experiments using this approach don't show considerable improvements in retrieval effectiveness but the authors believe that more experimentation is needed.
Another linguistic phenomenon that reduces the effectiveness in retrieval, particularly the recall, is synonymy, i.e having multiple words or phrases to describe the same concept. Thesauri containing synonyms, generalizations, specialization of terms or other related information have been used to approach this problem [14] [8].
NLP techniques for syntactic analysis have been used in information retrieval to index text by more complex elements than simple words, like noun phrases. Templates [5] And parsing techniques [25] [24] have been used to determine the boundaries of noun phrases and use them to index text and queries. Syntactic analysis in information retrieval is mostly restricted to noun phrases and so, is simpler than what is usually required in NLP applications. It has not been demonstrated, however, that any of these syntactic indexing techniques significantly improves retrieval performance.
One problem of indexing by noun phrases is that there are many different syntactic forms to express the same concept (e.g. `information retrieval and `retrieval of information'). Thus, finding similarities between two noun phrases that refer to a similar concept is a very difficult process. The phrase must have the same syntax structure in both the document and the query in order for the concept to be matched and this situation rarely happen.
The other problem is the fact that queries normally denote supersets of what the relevant document denote [10]. If the query is "software engineering methods" we want among others all the documents about "object oriented software engineering methods". The syntactic structures of the query and of the expression making up the documents will be different and we need some kind of syntactic correlation of the semantic superset/subset relation.
One approach to these problems is to normalize the syntax structures to get a canonical form. Noun phrases like "information retrieval" and "retrieval of information" give raise to the same canonical or dependency structure and can therefore be retrieved by the same query. This approach is taken by the CLARIT system [6] where text and queries are indexed by noun phrases in a normalized form. Input text is parsed and candidate noun phrases are identified. These noun phrases are normalized by mapping them into canonical frames (reflecting their lexical semantics), emphasizing modifiers and head relations. Resulting terms are matched against a thesaurus with the terminology (essentially a phrase list) of an specific domain. Through the match, terms are classified as either exact (identical to some phrase in the list), general (terms in the list are part of the candidate term) and novel (new terms not in the list which are potential new index terms). Except for a small subset, the thesaurus is constructed automatically from documents in a specific domain and using CLARIT-based processing.
Experiments on retrieval by syntactic phrases have shown poor results. Furthermore, experiments on retrieval by statistical phrases exhibit better effectiveness than purely syntactic methods for information retrieval [7]. Salton [23] stated that "syntactic systems not based on contextual and other semantic considerations cannot be completely successful in eliminating ambiguities and constructing useful indexing units". Even if the application of pure syntactic analysis techniques in information retrieval has not shown real improvements in retrieval effectiveness, syntactic techniques have demonstrated their usefulness as auxiliary mechanisms for semantic processing like caseframe parsing. Syntactic methods are used in order to take advantage of the text structure, to link words (e.g. how an adjective is linked to a noun, etc) and to resolve some problems related to negations, conjunctions, etc.
Former approaches of semantic processing in information retrieval were based on the definition of a formal language (unambiguous, with simple rules for interpretation and having a logical structure) into which input text could be turned. More recently, knowledge representation frameworks from artificial intelligence, like semantic networks and frames have been used to represent knowledge by specifying primitives or simple concepts and then combining them to define more complex concepts.
Most information retrieval system that use semantic analysis techniques are conceptual information retrieval systems [13] [19]. In conceptual information retrieval the user requests information, and is given the information directly, not just a reference to where it may be found. The most common semantic representation structures used in information retrieval are case frames [13] [26] [12] and scripts [16].
The main difficulty of semantic analysis is the large amount of knowledge needed to process the meaning of a sentence. For that reason, semantic analysis usually is done only in a restricted domain using a knowledge base manageable in size and complexity.
A first prototype of the retrieval system is being constructed in BIMProlog [22] and using the WordNet public domain thesaurus. Our purpose is to make an analysis of the effectiveness of our retrieval approach by using alternative matching algorithms and alternative similarity measures. We also want to compare the behavior of our system with the one exhibited by traditional keyword-based retrieval systems.
Although we plan to experiment initially with retrieval from natural language specifications that describe simple actions performed by a computer, we expect to construct flexible mechanisms that can be applied to the retrieval of more complex code components and software development information with higher leverage, like design and requirements specifications.
Site Hosting: Bronco